La nascita e l'evoluzione dell'Internet



- La nascita della 'rete' informatica
- Il primo computer totalmente elettronico
- Il progetto ARPANET
- I protocolli TCP/IP
- La fine di ARPANET e la nascita di Internet
- Linguaggi e comunicazione
- Un linguaggio per far comunicare le macchine
- Linguaggi di programmazione di alto livello
- Linguaggi di programmazione di basso livello
- I protocolli di comunicazione
- Il Transmission Control Protocol
- Server e client
- L'Internet Protocol e l'indirizzo IP
- L'iPv4
- La scheda di rete
- IP pubblici e locali
- IP shortage?
- Network Address Translation
- Mainframe e server
- Webfarm e mainframe
- L'Internet
- Posta elettronica
- Internet Relay Chat (IRC)
- I canali IRC
- File Transfer Protocol (FTP)
- World Wide Web e l'Hyper Text Transfer Protocol (HTTP)
- La nascita del World Wide Web
- Hypertext Markup Language (HTML)
- Gli editor HTML
- Domain Name System (DNS)
- BitTorrent
- Come funziona il protocollo BitTorrent
- Voice Over Internet Protocol (VoIP)
- Servizi proprietari per utenze massive
Contattami velocemente
per richiedere una valutazione GRATUITA del tuo problema!

Il mondo l'abbiamo connesso. Le persone ancora no.
La nascita della 'rete' informatica

Tanto tempo fa, agli albori dell'informatica, la computazione elettronica era affar serio solo per la ricerca scientifica, in particolar modo applicata ai progetti universitari e militari.
Per via dell’altissimo costo di progettazione e costruzione delle prime macchine da calcolo, tutta la ricerca era concentrata solo nelle istituzioni che potevano realmente permettersi di sborsare ingenti somme di denaro e costo umano nella realizzazione di ingombranti prototipi buoni solo ad eseguire dispendiosi, seppur estremamente interessanti, calcoli matematici.
Tutto ciò era di enorme interesse per le università, e nel periodo della cosidetta 'guerra fredda' (quando le due superpotenze mondiali USA e Unione Sovietica si contendevano a minacce atomiche il mondo) la cosa cominciò a divenire succulenta anche per le organizzazioni governative.
Senza dubbio, possiamo ben affermare che, per quanto strano ora possa risultare, l'avanzamento tecnologico che ci ha portato all’informatica di massa sia figlio diretto della competizione militare tra blocco occidentale blocco sovietico degli anni ’60 e ’70 del 1900.
 L'ENIAC, il primo calcolatore totalmente elettronico costruito dall'uomo
L'ENIAC, il primo calcolatore totalmente elettronico costruito dall'uomoIl primo computer totalmente elettronico
Grazie alla costruzione dell’ENIAC, il primo vero calcolatore totalmente elettronico della storia (qui c'è un interessante approfondimento sull'argomento) per la prima volta nella storia l’uomo era riuscito a creare una macchina da calcolo completa totalmente elettrica, senza parti in movimento: questa mirabile prima opera costruita, benché ora possa apparire ridicola, fu comunque un pilastro importante nella giovane storia dell’informatica.
Il progetto ENIAC però, con la sua utilissima funzione di tracciamento dei missili, servì anche a realizzare un’altra grande intuizione che avrebbe contribuito all’espansione dell’informatica: la condivisione delle informazioni.
Sì, perché tutti i risultati delle elaborazioni dell’ENIAC venivano immediatamente recapitati agli organi di difesa americana competenti, in caso di attacco improvviso.
 Una scheda perforata, un tempo unico modo di inviare input ai calcolatori
Una scheda perforata, un tempo unico modo di inviare input ai calcolatori
Ovviamente, all’epoca strumenti di trasmissione telematica come e-mail, sms, WhatsApp e IRC ancora non esistevano (e neanche erano pensabili), quindi i risultati degli elaborati di ENIAC - direttamente in forma di schede perforate - venivano imbustati al volo, sigillati, messi nei cilindri di comunicazione e spediti per posta pneumatica a chi di dovere.
Ciò può essere considerato, in effetti, un prototipo rozzo e primitivo della posta elettronica, impensabile ai nostri tempi ma di rilievo sul finire degli anni ’40.
Qualche lustro poi, l’importanza dello scambio di informazioni tra calcolatori sarebbe diventato il pilastro fondamentale del famoso progetto ARPANET, la prima grande rete di scambio informazioni digitali, che sarebbe poi a sua volta diventata la 'rete delle reti', ovvero Internet.
Il progetto ARPANET
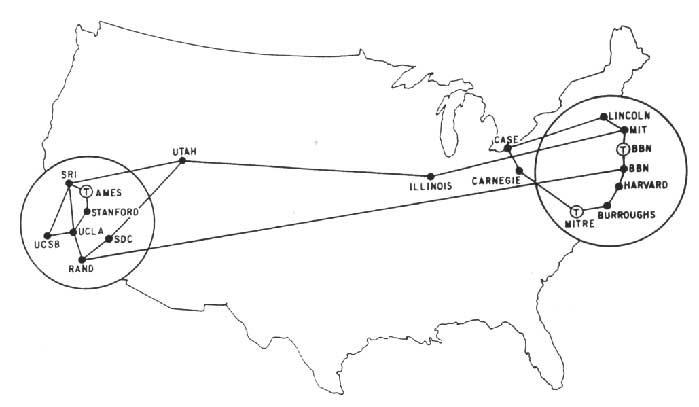 La rete ARPANET nel 1971
La rete ARPANET nel 1971Con l’avanzare della tecnologia, l’entrata in scena dei transistori, delle memorie logiche ed il conseguente cambio di rotta della ricerca informatica, i costi di ideazione produzione e si andarono via via assottigliando, facendo uscire la computazione elettronica dal monopolio prettamente scientifico e rendendola appetibile anche per altre applicazioni, ancora confinate però nella ricerca universitaria e militare.
Capita l’importanza della trasmissione di informazioni, sul finire degli anni ’60 quando ancora la paranoia di una crisi nucleare governava mezzo mondo, il Dipartimento della Difesa degli Stati Uniti d’America decise di provare a costruire una rete di calcolo attraverso tutto il Paese per coadiuvare ed agevolare lo scambio d'informazioni militari tra le forze armate... E non solo.
Sebbene per i generali e gli statisti dell’epoca questo non venne preso in minimo pensiero, la paura della 'guerra fredda' e di sopravvivere ad un attacco nemico fu la grande molla che fece iniziare la costruzione della più grande rete mondiale, che ancora tutti noi usiamo.
I protocolli TCP/IP
Il progetto della rete di calcolo ad uso militare si chiamava ARPANET, era l’acronimo di "Advanced Research Projects Agency Network" (Rete dell’agenzia dei progetti di ricerca avanzata) ed era ambizioso: costruire una grande rete americana che mettesse in comunicazione i calcolatori delle forze armate di tutto il territorio, possibilmente resistente ad un attacco nucleare sovietico.
In tempi in cui ogni ente universitario e militare usava calcolatori proprietari dalle più disparate architetture hardware e con software spesso totalmente dedicati, la faccenda era un affare serio.
Il team di sviluppo del progetto lavorò abbastanza infruttuosamente sul problema per circa una decina di anni, non trovando una soluzione adeguata che potesse far dialogare tutti i calcolatori con un unico linguaggio comprensibile da tutte le macchine, poi nel 1974 ci fu la rivoluzione: l'Università di Stanford, finanziata dalla DARPA, mise a punto un insieme di protocolli di comunicazione per l’interconnessione di calcolatori eterogenei.
Era appena nata la famosa Internet Protocol Suite, che conteneva in sè due protocolli che sarebbero in breve diventati lo standard mondiale della comunicazione tra calcolatori, ovvero i protocolli TCP ed IP, da subito accorpati in un binomio vincente ancora oggi conosciuto come TCP/IP.
Grazie alla suite di protocolli, il progetto ARPANET cominciò a decollare, tanto che nel 1974 i più importanti centri di ricerca sulle due coste americane erano collegati e si scambiavano dati di ogni natura: il primo abbozzo di quella che sarebbe diventata Internet era nato.
Il concetto stesso di rete informatica era finalmente realizzato: tutti i calcolatori collegati alla rete ARPANET (chiamati nodi) erano autonomi ed indipendenti, e nel caso che un attacco nucleare che avesse distrutto un nodo della rete, tutte le altre macchine da calcolo avrebbero potuto continuare ad operare senza problemi.
Questa dislocazione decentralizzata di ARPANET, essenziale a garantire la sopravvivenza della rete a seguito di un ipotetico attacco nucleare di massa, è tuttora usata nell’Internet, ed insieme al binomio TCP/IP ne é l’elemento portante.
La fine di ARPANET e la nascita di Internet
ARPANET partì con molte attese dalle soprintendenze militari, che la consideravano una potenziale arma vincente contro i russi, specialmente per lo stoccaggio di informazioni chiave in ambito bellico (mappature delle basi alleate e nemiche, comunicazioni militari, calcoli di test nucleari e balistici, e via discorrendo).
Dopo circa un lustro dalla sua creazione, la rete cominciò a manifestarsi abbastanza costosa e dispendiosa per soli fini militari ed invece abbastanza succulenta per i centri di ricerca universitari americani, entusiasti di poter condividere le loro scoperte e ricerche in tempi incredibilmente veloci con i loro colleghi dall’altra parte dell’America.
Fu così che dopo circa un decennio, ARPANET perse pian piano l’interesse del Dipartimento della Difesa per invece guadagnare consensi nel capo della ricerca universitaria.
Questo spostamento abbastanza importante degli interessi, unito al fatto della rapidissima diffusione dei primi 'Home Computer', dettarono la morte del progetto prettamente militare ARPANET in favore di un nuovo, grande progetto scientifico: Internet stava nascendo, e niente ormai poteva fermarla.
Linguaggi e comunicazione

Due o più calcolatori si dicono 'in rete' quando possono condividere tra di loro informazioni, di qualsiasi genere.
Documenti di testo, video, audio et similia altro non sono che quantità definite di byte, a loro volta formati da bit che di rimando sono visti da qualsiasi ALU (l'unità logica-aritmentica di un processore di calcolo) di una qualsiasi CPU come valori logici, e sono pertanto elaborati da porte logiche costruite con transistori e diodi, che computano algoritmi di costanti e variabili booleane.
Come ben sappiamo, tutto ciò rende possibile il calcolo elettronico.
Un linguaggio per far comunicare le macchine
Ma come gli esseri umani comunicano usando i linguaggi specifici della loro etnia o posizione geografica, così le istruzioni dei calcolatori (i software) per svolgere il loro compito di risoluzione di problemi necessitano di linguaggi specifici, chiari e non ambigui.
Questi linguaggi con cui i software sono costruiti si chiamano linguaggi di programmazione, che si dividono altresì in linguaggi ad alto livello e a basso livello.
Ogni software deve essere progettato per una specifica architettura hardware, ed in particolar modo per una detta CPU.
Le porte logiche dell’ALU della CPU possono intendere solo codice binario, che a sua volta deve essere comunicato in adeguato modo, con un particolare linguaggio.
Linguaggio che, essendo una serie considerevole di 0 e 1 può essere capito solo dal calcolatore, ed è chiamato codice macchina, oppure anche linguaggio macchina.
Siccome è praticamente impossibile per un essere umano operare sul codice macchina puro (anche se quest’ultimo è a tutti gli effetti un vero e proprio linguaggio), tutti i linguaggi di programmazione tendono ad usare semantiche e sintassi che, chi più e chi meno, tendono ad essere più amichevoli col cervello umano.
Linguaggi di programmazione di alto livello
Nei linguaggi di programmazione di alto livello, la semantica di scrittura è orientata di molto verso l’uomo, e non è comprensibile alla macchina: per questo tipo di linguaggi, è necessario quindi un software che interpreti il codice sorgente scritto dal programmatore e lo renda comprensibile per la macchina.
Queste sue caratteristiche speciali, rendono la scrittura ad alto livello indipendente dalla piattaforma hardware, e quindi grazie ad un software chiamato compilatore è possibile scrivere un dato programma per una piattaforma generica e poi convertirlo in codice macchina per una piattaforma specifica.
Se analizziamo meglio quanto detto, risulta palese che un applicativo scritto in uno dei tanti linguaggi ad alto livello disponibili può essere seguito dalla macchina in due modalità distinte:
- Attraverso un software che fa da interprete, e converte in tempo reale il codice sorgente in codice macchina.
L’esempio più classico è un qualsiasi file HTML: il codice viene interpretato immediatamente dal web browser all’apertura del documento. Il web browser si comporta quindi come un interprete in tempo reale; - Attraverso un software di compilazione, che converte il codice sorgente in codice macchina specifico per una data architettura e un dato Sistema Operativo. Il compilatore non è un interprete, e esegue la conversione prima dell’esecuzione del software.
Da questo, risulta chiaro che un software compilato per una determinata architettura ed un determinato Sistema non può essere eseguito da altre architetture ed altri OS.
Il software così compilato quindi, diviene una sequenza di bit impossibile da leggere per un essere umano ma molto chiara per la CPU: è per l’appunto un eseguibile binario.
Tra i tanti linguaggi di alto livello di programmazione presenti al mondo, vale la pena citare il C++, il FORTRAIN, Perl, Python e, con le dovute differenze in quanto è un linguaggio ad etichette, anche l’ormai essenziale HTML.
Linguaggi di programmazione di basso livello
Il linguaggio a basso livello di programmazione invece, è praticamente puro codice basilare che la CPU riesce a leggere senza troppi problemi: è più difficile da scrivere per un programmatore ma risulta molto logico per il computer, ed è sinora il modo migliore per avere totale controllo della CPU di un calcolatore, sin nei minimi dettagli.
Per scrivere in basso livello, un programmatore deve avere un'enorme conoscenza dell’hardware del calcolatore (in special modo della CPU) , in quanto nel linguaggio nulla deve essere lasciato al caso ma tutto è specificato in maniera perfetta e non ambigua.
Questo linguaggio, essendo discretamente comprensibile dalla CPU già a livello di codice sorgente, necessita di compilazione molto veloce e spartana.
I compilatori per tale linguaggio trasformano solo le istruzioni mnemoniche scritte dal programmatore in linguaggio macchina puro (sebbene anche questa sia una compilazione, è veramente poca cosa rispetto ai compilatori dell’alto livello).
Ne va da sè che un dato applicativo scritto in basso livello di programmazione è dedicato esclusivamente ad una data architettura hardware, e la conversione di software scritti in basso livello di programmazione verso una diversa architettura è cosa molto, molto difficile (quando non impossibile).
Storicamente, il linguaggio di programmazione a basso livello per eccellenza è l’Assembly, che è quanto di più vicino esista al linguaggio macchina inteso dalla CPU. Anzi, addirittura molte CPU possono capire senza particolari problemi molte istruzioni scritte direttamente in Assembly, senza bisogno di (seppur leggera) compilazione; compilazione che nel caso dell’Assembly viene fatta con il suo storico compilatore Assembler.
I protocolli di comunicazione

Capito come funziona la programmazione e che codice è in grado di leggere ed eseguire una CPU, risulta palese che tutti i calcolatori che debbano condividere informazioni si trovino dinanzi il grande ostacolo del linguaggio di comunicazione, che varia da architettura ad architettura.
Quest'ostacolo fu una vera spina nel fianco del progetto ARPANET, almeno sino al 1974 e alla messa a punto di una suite di protocolli di comunicazione che risolse il problema definitivamente; è bene notare che la Internet Protocol Suite, ormai vecchia di più di quarat’anni, è tuttora usata da tutti i calcolatori del mondo per condividere le informazioni non solo sull’Internet, ma anche nelle piccole reti domestiche o d’ufficio.
In informatica, un protocollo è una serie di regole scritte, chiare e definite allo scopo di permettere la comunicazione tra due o più dispositivi.
Effettivamente, se ben ci pensiamo la definizione di protocollo informatico non varia moltissimo dal significato dei comuni protocolli cartacei (contengono tutti e due informazioni scritte e ben definite, che spiegano nello specifico una determinata questione).
Sin dal 1974 quindi, tutti i calcolatori del progetto ARPANET hanno cominciato a condividere informazioni grazie ad un binomio di protocolli diventato nel tempo uno standard de facto per qualsiasi tipo di scambio dati, ovvero l’accoppiata TCP/IP.
Ora andremo a vedere nello specifico come funzionano entrambi i protocolli.
Il Transmission Control Protocol

Nella comunicazione tra due o più calcolatori, il protocollo che trasporta tutti i dati richiesti è il TCP, ovvero il 'Transmission Control Protocol' (Protocollo di Controllo del Trasferimento).
Il TCP può essere visto come la 'rotaia' che unisce idealmente i calcolatori presenti nella rete, su cui viaggiano le nostre informazioni; è quindi un protocollo di trasferimento perché non ci dice come i calcolatori debbono interpretare i dati che viaggiano su di esso, ma il suo compito è dettare gli standard per la via di comunicazione.
Risulta un po’ come una vera e propria autostrada, con tutti i riferimenti simbolici ad essa: cartelli di limite di velocità, corsie preferenziali o meno, numero di corsie, divieti, ecc ecc...
A tutto ciò fa capo il protocollo TCP, e le sue regole di trasferimento debbono essere recepite ed eseguite da tutti i calcolatori presenti in rete.
Le caratteristiche salienti del protocollo TCP sono:
- Commutazione dati a pacchetto: forse la caratteristica principale del protocollo TCP. Il flusso di byte che sono trasmessi via TCP sono frazionati in pacchetti dal calcolatore che li trasmette, che vengono ricomposti dal calcolatore che li riceve;
- Orientato alla connessione: Qualsiasi comunicazione che inizia tramite TCP deve prima essere stabilita attraverso la negoziazione dei calcolatori mittente e destinatario: ciò si chiama in gergo 'handshake', ovvero stretta di mano. Cosa importante da ricordare è che la connessione via TCP è sempre chiusa quando non più necessaria;
- Bidirezionalità: Le applicazioni dei calcolatori che comunicano via TCP possono contemporaneamente ricevere e inviare pacchetti di dati;
- Garanzia del trasferimento: TCP si prende la briga di controllare che i pacchetti che giungono a destinazione (se lo fanno) lo facciano in ordine e una volta sola;
- Multiplazione: TCP permette ad un calcolatore di effettuare più connessioni contemporaneamente verso altri elaboratori, facendo in modo che i pacchetti dati vengano spediti correttamente al processo sulla macchina che li sta aspettando. Questa fondamentale funzione è ingegnosamente attuata da TCP attraverso il sistema delle porte di rete.
Server e client

Da molti anni ormai TCP è incluso in qualsiasi Sistema Operativo esistente al mondo: questo ha permesso di far diventare il progetto ARPANET molto, molto più grande: Internet.
TCP non è l’unico protocollo di trasmissione esistente in informatica e anche lui ha dei bug e delle limitazioni, ma i suoi vantaggi sono talmente enormi che superano di gran lunga i suoi svantaggi.
Tutti gli applicativi che caricano in memoria processi che richiedono accesso alla rete (qualunque essa sia, da quella di soli due calcolatori all’Internet) sfruttano il protocollo TCP integrato nel Sistema Operativo.
Ma per le sue caratteristiche intrinseche, le due macchine collegate attraverso TCP prendono nomi differenti a seconda se inviano informazioni oppure le ricevono.
La macchina su cui i processi inviano una richiesta di connessione viene chiamata client, la macchina che sta in ascolto ed accetta la richiesta di connessione viene chiamata server.
È da sottolineare come, via TCP, un calcolatore può essere client o server a seconda del fatto che invii od accetti una richiesta di connessione: i ruoli sono sempre invertibili per altre connessioni future.
Per quanto possa sembrare semplice, TCP è tutto qui.
L'Internet Protocol e l'indirizzo IP

Se TCP è il protocollo che detta le regole di trasmissione dei flussi di byte in una rete, l’Internet Protocol (comunemente abbreviato come IP) stabilisce invece come i calcolatori debbano recepire ed elaborare le informazioni in trasmissione.
È anche esso un protocollo di rete a pacchetto, e le istruzioni del protocollo sono direttamente incapsulate nei pacchetti dei byte in trasmissione.
Nella sua più che quarantennale storia, il protocollo IP ha avuto differenti versioni: quella attualmente in uso comuneè la IPv4, mentre si sta cercando di migrare, non senza problemi, alla IPv6.
I nomi delle versioni chiariscono in maniera esemplare la grandezza in bit dei pacchetti dati spediti con IP: 4 bit per l’IPv4, 6 bit per l’IPv6.
L’accoppiata TCP/IP permette a macchine con architetture differenti e Sistemi Operativi non uguali di comunicare dati, a prescindere dalle loro caratteristiche intrinseche.
Spesso si fa confusione tra protocollo IP ed indirizzo IP, e l’ambiguità va chiarita.
Sebbene due parti della stessa moneta, come abbiamo visto il protocollo IP è una serie di istruzioni che ci dicono come due o più calcolatori debbono elaborare i byte che si scambiano, mentre l’indirizzo IP è un numero che identifica univocamente un qualsiasi dispositivo collegato ad una rete che comunica con il protocollo IP.
Usualmente, per spiegare il concetto di un indirizzo IP si prende ad esempio un’utenza telefonica oppure un indirizzo civico.
Gli esempi sono calzanti, in quando l’indirizzo IP svolge in rete le stesse funzioni di reperibilità univoca di un numero telefonico oppure di un civico stradale.
Ancora, l’indirizzo IP può essere visto come il Codice Fiscale personale che tutti i residenti della Repubblica Italiana hanno: come il Codice Fiscale identifica una e solo una persona, così l’indirizzo IP identifica in rete uno ed un solo calcolatore.
Che sia client o server poco importa, il calcolatore avrà comunque un indirizzo IP univoco, valido solo per lui.
Questo evita ovviamente confusioni generali tra molti calcolatori in rete (che può essere enorme, come l’Internet), evitando il rischio di mandare informazioni a destinatari sbagliati.
Come nella vita di tutti i giorni è seccante sbagliar numero telefonico oppure strada, nell’informatica la faccenda può diventare ancora più irritante: per ovviare senza timore di sbagliare alla confusione, c’è l’indirizzo IP.
L'iPv4
Un generico indirizzo IP (versione 4) si compone sempre di una quaterna di numeri decimali da un byte l’uno, quindi 8 bit e quindi 256 possibili combinazioni che vanno da 0 a 255. Per facilitare la lettura, ogni gruppo di numeri è separato da un punto.
Ecco un classico esempio di indirizzo IP di quarta versione:
82.128.234.34
Questo è un classico IP pubblico, di una macchina connessa all’Internet.
Nello specifico, va chiarito che una macchina connessa all’Internet si chiama host.
Di rimando, per divenire un host un calcolatore deve avere assegnato un indirizzo IP valido, con cui è visibile dagli altri dispositivi; parliamo di dispositivi e non solo di calcolatori puri perché ormai ci sono centinaia di apparecchi che, sebbene non progettati principalmente per il calcolo elettronico, possono connettersi ad una rete con TCP/IP.
La scheda di rete
Ancora sempre più specificamente, un qualsiasi dispositivo per allacciarsi ad una qualsiasi rete informatica deve avere l’hardware adeguato: la famosa scheda di rete, o 'network card' in inglese.
Ci sono tantissimi tipi di schede di rete, per tantissimi dispositivi: ne troviamo cablate con ethernet, firewire, con cavi coassiali, in fibre ottiche e wireless... E la lista è bella lunga.
Quale che sia la scheda di rete fisica, per divenire un host il dispositivo deve per forza vedersi assegnato un indirizzo IP valido.
Tutti gli host del mondo compongono l’Internet, ovvero la più grande Rete globale attualmente esistente.
IP pubblici e locali

Le combinazioni possibili con quattro numeri da 8 bit l’uno (per un totale di 32 bit) che garantisce l'IPv4 sono molte, ma di certo non infinite: possono infatti venire assegnati esattamente 4.294.967.296 indirizzi.
Questo numero di combinazioni negli anni ’80 era considerato difficilmente raggiungibile anche considerando tutte le macchine da calcolo presenti nel mondo, ma ovviamente dall’avvento dell’informatica di massa, del 'Personal Computer' e delle miriadi di dispositivi moderni che necessitano un indirizzo IP per connettersi all’Internet nella prima metà degli anni ’90, si è venuta a creare una situazione di preoccupazione per l’imminente carenza di indirizzi IP disponibili, conosciuta pure come 'IP shortage' (letteralmente: carenza di IP).
I principali fornitori di servizi telefonici mondiali (i colossi nord americani AT&T, SouthBell, Rogers, i colossi europei Telecom Italia, Orange, Deutsche Telekom, Vodafone e tanti altri loro colleghi sparsi in tutto il mondo), fiutando il grosso business della rampante crescita di Internet, hanno acquistato negli anni una quantità veramente spropositata di indirizzi IP, lasciandone ben pochi a disposizione per i nuovi concorrenti ed anche per le utenze private.
IP shortage?
Tutto ciò, sommato al fatto di una diversa concezione dell’uso dell’elettronica, sempre più integrato nella vita comune per praticamente tutte le professioni umane, con quantità considerevoli di nuovi dispositivi che necessitano di un accesso Internet, ha fatto scattare la grande paura dell’IP shortage.
Per ovviare a questo, è dalla metà degli anni ’90 che si sono sviluppate massicciamente tecnologie specifiche per tentare di arginare il problema.
Tra queste, a parte la nuova versione del protocollo IP (la 6) che ancora fatica ad entrare nell’utenza comune, sicuramente la tecnologia NAT ha aiutato molto ad impedire l’IP shortage e, diciamolo, a facilitare di molto la nascita delle piccole reti d’ufficio o domestiche che tutti usiamo nel tempo attuale.
Network Address Translation

NAT, acronimo di 'Network Address Translation' (Traduzione Indirizzi di Rete) è una tecnica specifica che agisce sui pacchetti che viaggiano sul protocollo IP, modificandone gli indirizzi tramite un dispositivo apposito che si chiama router.
In parole poverissime, il router grazie a NAT prende un dato indirizzo IP da una scheda di rete e lo 'spezzetta' in tanti sotto-IP (chiamati IP locali) quante sono i dispositivi della rete, facendoli uscire da una seconda scheda di rete dedicata.
Ovviamente, tutti i processi che richiederanno una connessione all’Internet non si collegheranno direttamente all’host, ma bensì si connetteranno all’IP del router che a sua volta provvederà ad indirizzare il processo verso l’host richiesto.
A loro volta, tutti i calcolatori si vedranno e comunicheranno tra di loro sempre grazie ai loro IP locali dati dal router.
Tutto questo ci può far intendere che una data rete di computer connessi tra di loro tramite un router con tecnologia NAT è comunque una rete locale: LAN in inglese, ovverosia 'Local Area Network'.
Il router che gestisce la LAN deve avere assegnato un indirizzo IP pubblico per esser riconosciuto nell’Internet: quindi possiamo ben immaginare la nostra LAN come un’unica entità, visibile sull’Internet con l’indirizzo IP pubblico del router.
Semplice, efficace ed estremamente utile.
Questo sistema permette, con un solo indirizzo IP pubblico, di mettere in rete tanti calcolatori, ed è stata la chiave di volta nell’abbassamento dei prezzi di accesso dei provider e della rapida ed irrefrenabile diffusione di tantissime LAN private, più o meno grandi, a loro volta collegate all’Internet da indirizzi IP pubblici.
Solitamente, l’indirizzo IP di default di ogni router è il classico 192.168.2.1 ma si può sempre cambiare secondo le esigenze di rete.
Le modalità di connessione fisica di una LAN sono molteplici, come molteplici possono essere le schede di rete di un router.
Un tempo esclusivamente cablate (solitamente tramite connessione ethernet), oggi si trovano LAN miste, wireless, USB, fibra ottica, ecc. ecc.
Non c’è un sistema fisico migliore di un altro, ma come sempre in informatica tutto deve essere rapportato all’inevitabile rapporto vantaggi/svantaggi.
Mainframe e server

Se per le piccole utenze domestiche e d’ufficio spesso e volentieri un buon router con un ragionevole costo risolve ogni problema, per grandi aziende o grandissime utenze c’è bisogno di soluzioni particolarmente avanzate, con macchine e software specifici.
Come abbiamo visto in precedenza, in un collegamento via TCP un dispositivo i cui processi avviano una richiesta di connessione è chiamato client, mentre il dispositivo che risponde alla richiesta è chiamato server.
Abbiamo già detto che qualsiasi calcolatore sotto TCP può essere client o server a seconda dell’invio o della richiesta di connessione.
Detto questo, possiamo ben immaginare una macchina con hardware e software particolare, che si metta sempre all’ascolto di richiesta di connessione e le soddisfi al suo meglio: esatto, una macchina solo con compiti di server.
Questo calcolatore specifico fungerà da nodo centrale di tutta la nostra LAN, ed avrà anche compiti di router: smisterà le richieste ad indirizzi IP pubblici, fornirà sotto-IP locali, permetterà alle macchine presenti nella rete di comunicare e vedersi tra di loro con certi privilegi, metterà a disposizione dei computer le risorse di lavoro dedicate (stampanti, volumi di archiviazione di massa, ecc ecc...).
Ancora, può anche prendersi cura dei servizi basilari dell’Internet che vedremo tra poco, come il servizio e-mail e uno spazio hosting per il web. Quindi sarà anche una macchina host.
Questo fa un di un calcolatore un server, che per svolegere al meglio il suo lavoro solitamente possiede un Sistema Operativo speciale, particolarmente dedicato ai servizi di Internet e con potenti strumenti di gestione delle reti.
Allo stato attuale delle cose, quasi tutti i principali Sistemi Operativi in commercio per computer client hanno anche una versione dedicata per calcolatori solo server: tra questi, probabilmente le varie distribuzioni server di GNU/Linux occupano una fetta di mercato considerevole, seguite a ruota da le varie versioni server dei prodotti Microsoft Windows e, in versione minoritaria, dalla Apple con le sue versioni di MacOS.
Webfarm e mainframe
Non è raro trovare anche aziende con calcolatori server fuori sede, magari gestiti in concessione da fornitori appositi di servizi di housing: in pratica sono degli enormi capannoni industriali pieni zeppi di host con vagonate di gruppi continuità, router ad alta velocità per la connessione degli host e ambiente rigorosamente a temperatura adatta per evitare la troppa dissipazione di calore.
A loro volta, i server possono essere messi in comunicazione tra di loro, creando una sotto-rete solo di server.
Quando invece una specifica azienda o corporazione ha un numero enorme di utenti che ogni giorno e che ogni secondo fanno centinaia di migliaia di richieste d’accesso ad uno specifico host, v’è bisogno di un calcolatore server molto potente per fornire tutti i servizi in tempi rapidi ed efficienti.
In questo caso, si parla di mainframe.
Un singolo mainframe può rimpiazzare senza problemi dozzine di server, e è capace di ospitare al suo interno diversi Sistemi Operativi mediante la tecnica della virtualizzazione.
Queste macchine hanno solitamente costi proibitivi anche per le medio-grandi aziende, sono quasi sempre sviluppate da IBM (che detiene qualcosa come circa il 90% del mercato dei mainframe), sono costosissime nella manutenzione ma offrono prestazioni, scalabilità e efficienza impareggiabili.
Il loro altissimo costo le rende alla portata solo di grandi gruppi finanziari, bancari o governativi.
L'Internet

Come abbiamo ben visto, Internet non è che una gigantesca rete di calcolatori che comunicano tra di loro con protocolli standard, principalmente tramite l’accoppiata TCP/IP.
Un qualsiasi dispositivo connesso all’Internet con protocollo IP deve per forza aver assegnato un indirizzo IP valido: in questo caso, sappiamo che la macchina si chiama host.
Sappiamo inoltre che, grazie ai vari router, server et similia, gli indirizzi IP pubblici possono essere smistati verso le reti private in una serie di IP locali.
Con i mente tutto ciò, cosa può farci fare Internet?
Beh, come un calcolatore può fare ciò che gli applicativi in esecuzione su di esso possono fare, così l’Internet può fare ciò che i suoi host collegati in rete possono fare, e la cosa sembra ovvia.
Nello specifico, alle cose che gli host permettono di fare in rete viene dato il nome di servizio, ed ora andremo proprio ad analizzare i servizi più rilevanti.
Allo stato attuale della rete, possiamo senza remore di smentita considerare che i seguenti servizi compongono più del 90% di tutto il traffico Internet.
Alcuni di essi sono storici, altri si sono aggiunti di recente, ma è bene sempre ricordare che ognuno di essi è sempre reso possibile da un sistema di sever/host che ne permettel’esecuzione.
Andiamo quindi ad analizzarli senza indugio.
Posta elettronica

Lo storico servizio di Internet che permette di scambiare documenti di testo elettronici (mail) comprensivi di svariati allegati, tipo file di foto, audio, video e, in generale, qualsiasi dato.
Il servizio ha riconosciuta la sua paternità in Ray Tomlinson che nel 1972 circa installò su ARPANET il primo server per il servizio di scambio messaggi tra le varie università americane.
Il suo funzionamento è molto semplice, così come la sua facilità d’uso che l’ha fatto diventare il servizio più amato ed usato della Rete.
Ogni utente del servizio ha una propria casella di posta virtuale (account) su uno specifico spazio su un host (hosting), associato ad uno specifico dominio (vedremo poco più avanti cosa è un dominio): solitamente, è possibile creare un numero indefinito di account per ogni dominio.
L’utente titolare dell’account, grazie a specifici software, può connettersi al proprio server e scrivere, inviare e ricevere messaggi elettronici da altri account; usualmente, la connessione al proprio account di posta elettronica è regolato da un sistema di protezione con nome utente (username) e chiave di accesso (password).
Un generico account e-mail si può riconoscere dalla sua sintassi: si prenda ad esempio l’account fittizio
mariorossi@serviziomail.it
In questo caso, 'mariorossi' è il nome specifico della casella di posta (username) il famoso simbolo @ (chiocciola in italiano) sta in inglese per 'at' (a, inteso come in direzione di) e 'serviziomail.it' è il nome DNS del server che ci gestisce il servizio e a cui dobbiamo accedere per consultare ed inviare i nostri messaggi. Tutto qui.
I software specifici che ci permettono di accedere al nostro server, e che ci danno anche tanti strumenti potenti per editare i nostri messaggi, sono chiamati e-mail client, e ce ne sono a decine per ogni genere di Sistema Operativo.
Un qualsiasi e-mail client moderno è un programma molto potente che ci consente ampie scelte di formattazione del testo, modifica in bozze, gestione della posta indesiderata, filtri anti-spam (spam, gergo tecnico per messaggio non desiderato), gestione degli allegati e via discorrendo.
Una generica casella mail può essere dotata dei servizi cosidetti 'push', se il fornitore dell'account ha integrato la tecnologia nelle proprie offerte.
Un'email push si differenzia da un'email tradizionale per il fatto che il messaggio in arrivo, una volta ricevuto dal server, è da esso immediatamente reso disponibile ed inviato a tutti i dispositivi che sono stati configurati con l'account push.
Questo permette di ricevere i messaggi in maniera immediata, senza aspettare il controllo manuale (od automatico del client ogni tot di minuti).
Ogni Sistema Operativo contemporaneo ha almeno un e-mail client integrato, ma in eete se ne trovano di tanti tipi, a pagamento e gratuiti, a seconda dei gusti ed esigenze.
Per dovere di cronaca, ricapitolamo i più famosi software che sono Outlook Express per i Sistemi Microsoft Windows, Mail per i Sistemi MacOS e Mozilla Thunderbird per quasi tutti i Sistemi esistenti.
La lista sarebbe veramente lunga quindi verrà omessa, ma tra tutti come non ricordare uno dei primi client disponibili per il popolo: Eudora, ormai non più sviluppato.
Per concludere il discorso e-mail, è bene ricordare che è moda recente quella di molti provider di servizi di posta elettronica di fornire accesso ai propri server dedicati anche via HTTP tramite apposito pannello web, facilitando di molto quindi la gestione della propria casella e-mail anche quando non fisicamente connessi al proprio dispositivo preferito.
Internet Relay Chat (IRC)

Altro storico servizio di Internet, se la batte da sempre con il servizio di e-mail per la palma di primo servizio assoluto fruibile da tutti sulla rete.
È un servizio di messaggeria istantanea, ovverosia al contrario delle e-mail (che vengono spedite e solo poi, a discrezione del ricevente, consultate) i messaggi spediti vengono recapitati in tempo reale, appena inviati al destinatario che li può leggere immediatamente.
I server che consentono il servizio sono moltissimi e sparsi in tutto il globo, e tra di loro formano delle gigantesche reti IRC usate (come la posta elettronica) da milioni di utenti.
Storicamente, IRC è diventato famoso per essere stato il primo servizio (ancora sotto la morente ARPANET) ad essere usato attivamente per scambiare in tempo reale informazioni dalla defunta URSS anche in presenza di black-out televisivi e radiofonici.
Una finzione cinematografica romanzata di IRC si può trovare nel film degli anni ’80 “Jumpin’ Jack Flash”, in cui il servizio all’epoca fantascientifico fa da colonna portante di tutta la pellicola.
A differenza del servizio di e-mail in cui è richiesta un'autenticazione per accedere, generalmente i server delle reti IRC non richiedono nessun login, ma si limitano a far specificare all’utente un soprannome da utilizzare in chat: il cosidetto nickname.
Ogni rete di server IRC è a sua volta divisa in server (solitamente a valenza nazionale dati dai vari provider), che a loro volta mettono a disposizione canali dai più svariati temi per gigantesche chat di gruppo.
I canali IRC
In un canale IRC non tutti gli utenti godono degli stessi diritti: troviamo infatti utenti speciali, i cosidetti moderatori di canale (operatori oppure semplicemente 'op') che possono eseguire azioni impossibili per gli altri utenti come: cacciare gli utenti dal canale (kick), impedire l’accesso al canale di tutti gli utenti oppure di qualche utente specifico (ban) modificare il topic del canale, impedire agli altri utenti di scrivere (voice) e, più in generale, decidere al condotta del canale (netiquette).
In certe reti abbastanza anarchiche, un canale IRC si crea immediatamente quando un utente accede col comando /join #nomecanalescelto: questa caratteristica, unita al fatto che il primo che entra è op di default, ha portato molti programmatori a sviluppare software automatici perennemente connessi al canale (robot o bot), che impediscono che il canale venga chiuso ed aperto da altri per prenderne il controllo.
Sino a poco tempo fa popolarissimo, oggi grazie ai nuovi network sociali sul web e ai software specifici di chat istantanea (in particolar modo Facebook, WhatsApp e Skype) è ormai semi-sconosciuto ai più, in un declino che sembra non aver cenni di ripresa.
Praticamente primo grande strumento di massa per le comunicazioni sotto protocollo IP in tempo reale, ha visto la sua quota di popolarità scendere da livelli di assoluto predominio alla quasi scomparsa attuale negli usi della gente comune.
Sicuramente, l’avvento dei network sociali, che solitamente offrono più servizi di IRC, ha avuto un ruolo chiave nella sua rapida discesa.
Per accaparrarsi lo 'zoccolo duro' degli utenti IRC, ultimamente diversi server IRC offrono i loro servizi anche via web, ma i risultati non sembrano essere soddisfacenti.
Tra i software client per i Sistemi Operativi invece, per le piattaforme Microsoft Windows è storico il famoso mIRC, mentre per MacOS e GNU/Linux rimane sempre popolarissimo xChat.
File Transfer Protocol (FTP)

Altro storico servizio dell’Internet, sempre risalente al progetto ARPANET che è stato testato per la prima volta nel 1971 e ha subito una grossa evoluzione nel corso degli anni.
Consente di inviare e ricevere file di vario genere (audio, testo, video, foto, ecc ecc...) da e verso un server host, in maniera diretta e in codifica binaria: un server FTP può essere pubblico o privato, nel caso per l’accesso è richiesto anche in questo caso di farsi riconoscere tramite login con username e password.
Un server FTP generico ha la sua sintassi similare a ftp.mioserver.com.
Il servizio è usato per miriadi di scopi, tra i tanti vale la pena citare l’upload ed il download di file sorgenti dei siti web, per sostituzione, modifica o altro.
Anche in questo caso, troviamo tantissimi client FTP sul mercato, alcuni a pagamento ed altri gratuiti; ancora, molti Sistemi Operativi permettono di connettersi ad un dato server FTP direttamente dal loro file manager.
Nei sistemi basati su UNIX, qualsiasi shell può connettersi in FTP verso un dato server e scambiare dati.
Tra i client grafici FTP più famosi, ricordiamo Cyberduck per MacOS (gratuito, open source e molto potente) e l’altrettanto potente CuteFTP per i Sistemi Microsoft Windows.
Ancora, quasi tutti gli editor HTML di un certo rilievo (come Adobe Dreamweaver) hanno integrato anche il servizio di trasferimento FTP, mentre svariati web browser (quasi tutti) permettono almeno di visualizzare directory su server FTP e scaricarne i contenuti.
World Wide Web e l'Hyper Text Transfer Protocol (HTTP)

Assieme alla posta elettronica, il servizio più conosciuto ed utilizzato della rete.
Permette di trasferire file di ipertesto (hypertext) scritti in codice HTML, con cui a loro volta sono costruiti tutti i siti che formano il World Wide Web (conosciuto abbreviato anche come www, letteralmente: la Grande Ragnatela Mondiale).
Parlare del World Wide Web come uno dei tanti servizi di Internet ha poco senso, in quanto già di per se il servizio è un’insieme molto vasto di servizi.
Grazie alla grandissima duttilità del protocollo che lo trasporta, l’HTTP, unita alla teoricamente infinita possibilità del linguaggio HTML ed i suoi derivati (come l’XHTML, incrocio tra XML e HTML), per tacer della considerevole serie di moduli aggiuntivi come Javascript, Quicktime, le decine di soluzioni framework già pronte (ad esempio, le librerie JQuery), la sempre più stretta connessione con i linguaggi lato server (come il PHP oppure l’ASP) il web è molte, moltissime cose.
La nascita del World Wide Web
La nascita del servizio si fa convenzionalmente coincidere il 6 agosto del 1991, quando un giovane ricercatore del CERN di Ginevra nomato Tim Berners-Lee mette on-line (letteralmente: in linea) il primo server web della storia.
In quel caldo agosto di molti anni fa, chi avesse avuto accesso ad un host Internet digitando l’opportuno indirizzo IP in un rudimentale web browser si sarebbe potuto imbattere nella schermata sotto riportata: era il primo sito web della storia.
Molti anni dopo, quella striminzita pagina HTML si sarebbe duplicata in milioni di copie, sviluppate da centinaia di migliaia di programmatori: al solo testo si sarebbe aggiunta la grafica, suoni, miriadi di script, applet, filmati, interazione con l’utente...
Insomma, il web come lo intendiamo ai nostri giorni.
Ora noi diamo tutto questo per scontato e dovuto, ma dobbiamo ricordarci per bene che, in fondo, il web rimane tuttora una gigantesca, enorme, sterminata biblioteca di pagine HTML.
Tutti i documenti disponibili sul web sono mediati dal protocollo HTTP, le cui specifiche sono dettate dall’organizzazione internazionale World Wide Web Consortium (abbreviata anche in W3C).
Essenzialmente il protocollo trasporta documenti HTML, ma all’occorrenza permette di trasferire anche svariati altri documenti (solitamente incorporati nelle pagine HTML che li contengono).
Hypertext Markup Language (HTML)

È il linguaggio ad etichette ('markup language') più famoso al mondo, e serve a costruire fogli elettronici trasportati dal protocollo HTTP nell’Internet e creare così la ragnatela del web.
Ogni documento HTML termina con l’estensione .html oppure .htm, ed è in poche parole un foglio di testo elettronico con dentro il codice che descrive come un software interprete deve stampare a video la pagina.
Per questa sua caratteristica di essere totalmente slegato alla piattaforma hardware sulla quale è scritto, HTML è un esempio calzante di linguaggio di programmazione ad alto livello, e per essere eseguito su un calcolatore deve essere interpretato in tempo reale.
Gli interpreti dei documenti HTML sono chiamati web browser che permettono all’utente di ignorare il codice scritto e visualizzarne in tempo reale i dettami grafici.
Storicamente, il primo browser mai realizzato capace di visualizzare abbastanza decentemente anche i contenuti mediali (nello specifico: foto in .jpg) fu il famoso Mosaic, che in brevissimo tempo diventò l’altrettanto famoso Netscape Navigator, che regnò come re incontrastato del web sino alla fine degli anni ’90.
Il linguaggio dell’HTML è fortemente dedicato all’ipertesto, che ne risulta la colonna portante.
L’ipertesto è una tecnica che permette la giuntura non lineare dei documenti elettronici: grazie a particolari collegamenti chiamati per l’appunto hyperlink, è possibile passare direttamente da una parte di un documento all’altra, se non addirittura passare ad altri documenti, o altre parti di un altro documento.
Il tutto a discrezione del programmatore, che può decidere di indirizzare i collegamenti come meglio crede, non seguendo un ordine lineare preciso.
L’HTML è un linguaggio ad etichette perché tutte le istruzioni vengono scritte dal programmatore per mezzo di funzioni definite a priori, dalla semantica standard ed inequivocabile: sono i famosi tag HTML, che si possono riconoscere facilmente dal nome del tag racchiuso dalle parentesi < >.
Ogni tag HMTL per essere regolarmente letto ed interpretato dal browser in uso deve essere aperto e richiuso: nel mezzo del tag, il programmatore può mettere ciò che risolve un determinato problema.
Quando un tag si chiude, deve essere specificato con uno slash / dopo la prima parentesi e prima del nome del tag.
Gli editor HTML
Per costruire un foglio elettronico in HTML basta poco: serve solo un buon editor di testo, gli allegati (se richiesti) da inserire nella nostra pagina ed un web browser per testare il nostro codice.
Praticamente, tutto il resto è superfluo.
Possiamo scrivere un documento HMTL con un qualsiasi editor di testo presente nei nostri Sistemi, come ad esempio il famoso Wordpad di Microsoft Windows o l’altrettanto famoso TextEdit di MacOS, per non parlare del popolarissimo Emacs che è disponibile per praticamente tutte le piattaforme operative più famose, ma nella rete si trovano moltissimi altri tipi di editor testuali.
Possiamo scrivere tutte le nostre pagine HTML partendo sa semplici documenti di testo piatto ASCII, e salvando poi il tutto con l’estensione .html o .htm.
Altro tecnicamente non servirebbe.
La scrittura di codice HTML però, sebbene fortemente orientata verso l’utente e di facile apprendimento, è un pelino troppo difficile da maneggiare quando il documento supera le centinaia di righe di codice: per questo motivo nel corso degli anni son stati sviluppati un’enorme quantità di software dedicati esclusivamente alla scrittura di codice HTML, che aiutano i programmatori a districarsi meglio tra le migliaia di righe di codice di un sito completo e fornendo agli sviluppatori potenti strumenti per migliorare la resa del lavoro.
Sono i famosi HTML editor, tra cui il più famoso di tutti è Adobe Dreamweaver.
Complice l'informatizzazione delle masse, e la sempre più crescente richiesta di siti web anche da parte di chi non ha mai programmato prima, nel corso degli anni sono stati sviluppati particolari software lato server semi-automatizzati, dall'interfaccia molto semplice e dalla gestione altrettanto facile: sono i CMS (Content Management System), ovverosia programmi che, caricati direttamente in un hosting web, permettono la facile scrittura di pagine HTML anche a chi è a digiuno di programmazione.
Tra i CMS più famosi ed utilizzati, vale la pena ricorda Wordpress e Joomla.
Domain Name System (DNS)
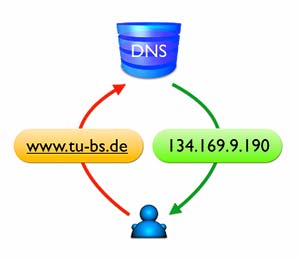
Servizio fondamentale che rende l’interazione dell’utente sul web molto più semplice.
In pratica i server DNS convertono i numeri degli indirizzi IP in 'parole', meglio conosciute come nomi DNS o nomi di dominio.
I domini DNS sono indubbiamente una delle caratteristiche più conosciute dell’Internet, e facilitano il ricordo mnemonico dei vari host della rete in quanto l’essere umano ricorda molto meglio le parole rispetto ai numeri.
Un generico indirizzo IP (fittizio) 33.24.123.23 convertito dai server DNS può diventare ad esempio miosito.com
Nell’esempio, 'miosito' specifica il dominio di secondo livello, mentre '.com' è il dominio vero e proprio, ed è di primo livello (top-level-domain o TLD).
Allo stato attuale delle cose, non esistono domini solo di primo livello e tutti devono essere almeno di secondo livello.
Sempre nell’esempio, il dominio di primo livello .com è un dominio generico, che può essere usato (previa registrazione e pagamento) da utenze private e pubbliche, per molti scopi e circostanze (dedicate o generiche).
Altri esempi di domini generici sono lo storico .net, il .biz e l’.info.
Poi ci sono i domini nazionali, assegnati a ciascun paese e il cui suffisso è di sole due lettere: nel caso della Repubblica Italiana, il domino di primo livello nazionale è il famoso .it.
Quasi tutti i TLD sono disponibili in tutto il mondo, ma ve ne sono alcuni che per ragioni storiche e politiche sono usati principalmente da certi Stati, come gli americani .gov, .mil, ed .edu.
Oltre ai domini di primo e secondo livello, ovviamente ne esistono anche di terzo: ad esempio, miosito.tuttomio.com è un dominio di terzo livello.
Al contrario dei domini di primo livello e come quelli di secondo, i domini di terzo livello possono essere scelti ed inventati liberamente dal compratore, a patto che siano ovviamente disponibili.
BitTorrent

Protocollo per la condivisione documenti su rete paritaria (peer to peer, anche abbreviato in P2P).
Per 'rete paritaria' si intende una rete dove tutti i calcolatori agiscono come nodi (peer), inviando le informazioni agli altri nodi della rete.
In questo contesto di scambio, non esistono computer client o server, ma ci sono solo nodi che passano o ricevono informazioni da altri nodi: quindi, la rete paritaria può essere considerata come l’esatto opposto della classica rete client/server.
Generalmente, le reti paritarie hanno scarsa applicazione nei sistemi industriali o commerciali (il controllo delle informazioni una volta messe in rete è praticamente impossibile, mancando di un server o di una catena di server), ma son divenute molto popolari come mezzo di condivisione di file, il cosiddetto file sharing (scambio di documenti).
Il protocollo BitTorrent è una delle ultime implementazioni di successo di rete paritaria, che sfrutta l’Internet per i suoi fini di condivisione.
Lo scopo del protocollo è fornire le massime prestazioni per la condivisione di qualsiasi file nella rete, e fa il suo mestiere lavorando sul fatto di distribuire un dato file al massimo numero di utenti possibili, sia che il file in questione sia in upload o in download.
L'obiettivo è quindi creare un vero e proprio 'torrente di bit' (da cui il nome) verso tutti i nodi della rete BitTorrent, massimizzando le velocità di ogni nodo.
Tutti gli utenti della rete BitTorrent infatti sanno che quando si riceve un particolare documento, al contempo si è parte del fiume di bit che compongono lo stesso.
Con questo sistema, le velocità dei trasferimenti sono di molto migliorate rispetto a qualsiasi altra rete peer to peer, e si possono scaricare senza particolari problemi anche file di grosse dimensioni (anche superiori al GB) in tempi ragionevoli, senza patire di snervanti lentezze di risposta server (o congestione dello stesso).
Come funziona il protocollo BitTorrent
Il protocollo BitTorrent è in realtà molto semplice: qualsiasi documento che si vuole condividere viene messo a disposizione direttamente nel proprio host, e reso pubblico grazie ad un piccolo file testuale di modeste dimensioni con estensione .torrent, che può essere condiviso con i sistemi consueti, ovvero via web oppure via FTP o ancora via IRC oppure come si vuole (anche offline, con scambio manuale oppure con la propria LAN).
Nel documento ci sono solo le informazioni del file completo (quanto pesa, di quante parti è composto, ecc ecc.) ed un URL del server di tracking (tracciamento): questo server serve solo a localizzare le sorgenti (i nodi della rete BitTorrent) che possiedono il file completo, oppure parti di esso.
Il file .torrent viene eseguito da un client BitTorrent (ce ne sono parecchi per praticamente tutti gli OS più famosi ed usati), che appena lo aprirà leggerà le informazioni in esso contenute, farà una richiesta al server di tracking per rintracciare tutte le fonti del documento da scaricare e poi avvierà il download.
Però, per iniziare il download, il client BitTorrent dovrà trovare sparsa per la rete almeno una copia completa di tutte le parti del file in interesse: questa copia è detta seed (seme) ed è utile per identificare al volo quanto un torrent sia buono per il download oppure no. Più seed, più copie complete disponibili, ovvero più flusso di bit, ovvero più dati, ovvero più velocità di eseguire il download completo della sorgente.
Con il protocollo BitTorrent, la condivisione automatica è forzata appena si contatta il server di tracking e si inizia il download, e tutto questo evita il monopolio di utenti poco onesti che scaricano ma non lasciano scaricare ad altri.
A ciò va aggiunto che non tutti gli host possono accedere alla rete BitTorrent, ma solo i dispositivi con una banda di connessione sufficientemente larga (questo per non rallentare gli altri nodi della rete).
Quindi, per usare il protocollo BitTorrent, a parte la già citata connessione in banda larga, è necessario avere il file .torrent con le informazioni del documento che si vuole ottenere e un client BitTorrent.
Di client BitTorrent ce ne sono a bizzeffe, ma sicuramente il più popolare e potente (sebbene leggermente macchinoso per i neofiti) è Vuze, precedentemente conosciuto come Azureus.
È disponibile per molti OS e svariate architetture, è gratuito e ha strumenti veramente potenti e completi (tra cui un motore di ricerca torrent integrato) che lo rendono estremamente configurabile a proprio piacere.
La grande velocità di condivisione, l’enorme numero di torrenti disponibili, la bontà di software client come Vuze e il bisogno di server centrale solo come tracking ha permesso al protocollo BitTorrent di scalzare ogni altro rivale per ciò che concerne il P2P e diventare il re della condivisione telematica.
Voice Over Internet Protocol (VoIP)

Servizio la cui data di nascita è incerta e dibattuta, comunque databile verso i primi anni ’90.
Tenuto abbastanza oscurato per un decennio complice la pochezza delle bande dell’epoca, dall’inizio del nuovo secolo le grandi industrie delle telecomunicazioni e le grandi software-house lo hanno rispolverato alla grande, e si può ben affermare sta soppiantando le tradizionali comunicazioni vocali analogiche.
Il grandissimo vantaggio di questa tecnologia è che evita di riservare spazio alla banda vocale per ogni telefonata (cosa che invece accade nelle reti telefoniche tradizionali), infilando i byte con le informazioni sonore nei pacchetti del protocollo IP.
Siccome è tutto smistato in digitale, con una buona larghezza di banda la qualità sonora delle comunicazioni è di gran lunga superiore a quella tradizionale; in più, la banda disponibile non usata dai pacchetti IP trattati con il VoIP può essere utilizzata per altro traffico di dati.
A tutto ciò, complice anche il fatto dell’abbassamento radicale dei costi di hardware di webcam e microfoni, si deve aggiungere anche l’estensione ovvia della chiamata solo audio, ovvero la videochiamata.
Negli anni, innumerevoli sono i client che possono permettere chiamate audio e video tramite VoIP: alcuni sfruttano protocolli aperti (come il SIP), altri proprietari (come Skype e tutti i principali client di messaggeria istantanea), ma tutti permettono ormai videoconferenze di altissima qualità (sempre a patto di avere adeguata banda).
Moltissime compagnie vendono anche numerazioni telefoniche tradizionali passandole sotto VoIP, e questo rende ormai senza senso il concetto di 'chiamata-distanza-costo' che ha tenuto su l’industria telefonica per più di un secolo.
Ormai client VoIP se ne trovano a bizzeffe per qualsiasi OS, ed ultimamente hanno sfondato il muro dei calcolatori per approdare anche sui nostri cellulari e tablet, trovando un terreno perfetto per la loro naturale vocazione primaria (parlare).
Un qualsiasi cellulare compatibile che usi il protocollo VoIP con un client compatibile (come Skype) e con decente connessione alla Rete rende il chiamare l’altra parte del mondo un piacere, e non un dolore per il portafogli.
Servizi proprietari per utenze massive

Rientrano in questa categoria (che negli ultimi anni ha visto un vero e proprio boom) tutti quei servizi che, sviluppati da compagnie private, riescono a soddisfare un numero enorme di utenze con le funzionalità più disparate.
Pensiamo agli innumerevoli software di messaggeria istantanea e social nwtwork che hanno quasi annichilito IRC (come Facebook e Skype), oppure alle gigantesche reti di server che si prendono cura di fornire accesso a milioni di persone interessate dal gioco online di massa: in tal senso, enormi utenze sono connesse tra di loro con reti di server proprietari e software specifici, come il Nintendo Network, XBox Live e Playstation Network.
Ancora, i server della software-house Blizzard che uniscono milioni di persone nel gioco massivo online più famoso, "World of Warcraft", per non parlare dell’ormai decennale rete che connette tutti i giocatori di "Quake III Arena", oppure di titoli multiplayer famossissimi con milioni di utenti connessi anche nello stesso momento, come la fortunata serie di "Call of Duty" o "Battlefield"... E la lista potrebbe continuare per svariate pagine.
Tutti questi servizi sono connessi grazie al protocollo TCP/IP, e hanno ampliato ancora di più la già enorme offerta dell'Internet.